InTDS ArchivebyYanli LiuOptimizing Small Language Models on a Free T4 GPUComprehensive Guide to Fine-Tuning Phi-2 using Direct Preference OptimizationJan 30, 20243Jan 30, 20243
InLevel Up CodingbyYanli LiuThe Art of Prompt Engineering: Using the 26 Principles in Everyday AI InteractionsExploring the 26 Principles for Enhanced LLM InteractionJan 9, 20247Jan 9, 20247
InTDS ArchivebyYanli LiuHow to Generate Instruction Datasets from Any Documents for LLM Fine-TuningGenerate high-quality synthetic datasets economically using lightweight librariesMar 6, 202414Mar 6, 202414
Manoranjan RajguruPrompt Template for OpenSource LLMsEach OpenSource LLMs are trained with predefined template , Hence its important you use the right template while you do inference.Jul 6, 2023Jul 6, 2023
InLevel Up CodingbyYeyu HuangThe 2-bit Quantization is Insane! See How to Run Mixtral-8x7B on Free-tier Colab.A Quick Tutorial for AQLM-2-bit Quantization and its ImplementationFeb 20, 20242Feb 20, 20242
Phillip GimmiWhat is GGUF and GGML?GGUF and GGML are file formats used for storing models for inference, especially in the context of language models like GPT (Generative…Sep 8, 2023Sep 8, 2023
Alejandro Núñez ArroyoRun Google Gemma + llama.cpp GGUF Inference in Google Colab 🦙Google has released its new open large language model (LLM) called Gemma, which builds on the technology of its Gemini models.Feb 25, 20241Feb 25, 20241
InTDS ArchivebyEduardo AlvarezImproving LLM Inference Latency on CPUs with Model QuantizationDiscover how to significantly improve inference latency on CPUs using quantization techniques for mixed, int8, and int4 precisions.Feb 29, 20242Feb 29, 20242
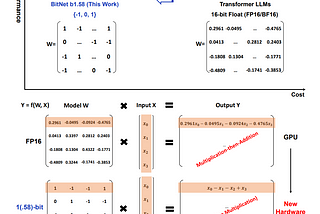
Inazhar labsbyazharNo more Floating Points, The Era of 1.58-bit Large Language ModelsThe world of Large Language Models (LLMs) is witnessing a paradigm shift, one that could redefine the very fundamentals of how these models…Feb 29, 20242Feb 29, 20242
InTDS ArchivebyMario LarcherDiffusion Transformer ExplainedExploring the architecture that brought transformers into image generationFeb 28, 20241Feb 28, 20241
InStackademicbyFabio MatricardiHow to Quickly Test a New LLM Without Wasting TimeSometimes you simply need to test them yourselfFeb 27, 2024Feb 27, 2024
InGoPenAIbyAgent IssueBGE M3 Embedding: The First Unified Model for Dense, Sparse and Multi-Vector RetrievalThe Beijing Academy of Artificial Intelligence (BAAI) has recently introduced the BGE-M3 model, the first of its kind to offer support for…Feb 5, 20241Feb 5, 20241
InTDS ArchivebyBenjamin EtienneA Complete Guide to Write your own TransformersAn end-to-end implementation of a Pytorch Transformer, in which we will cover key concepts such as self-attention, encoders, decoders, and…Feb 24, 202410Feb 24, 202410
BoredGeekSocietyFinally! 7B Parameter Model beats GPT-4!We are entering the era of small & highly efficient models!Feb 6, 202410Feb 6, 202410
InSyncedReviewbySyncedIntroducing NVIDIA’s Audio Flamingo, the Next Frontier in Audio Language ModelsUnderstanding sound is undeniably crucial for an agent’s interaction with the world. Despite the impressive capabilities of large language…Feb 11, 2024Feb 11, 2024
InThoughts on Machine LearningbyFS NdzomgaHow To Deploy Mistral 7B On AWS SageMakerExploring foundational models like GPT-4, LLaMa 2, or Mistral 7B via an API is straightforward and offers powerful capabilities. However…Feb 11, 2024Feb 11, 2024
Venkat Ram RaoFine Tuning a Sentence Transformer ModelA quick introduction to fine tuning Sentence Transformers for Semantic Search.Dec 22, 20231Dec 22, 20231
InBetter ProgrammingbyWenqi GlantzFine-Tuning Your Embedding Model to Maximize Relevance Retrieval in RAG PipelineNVIDIA SEC 10-K filing analysis before and after fine-tuning embeddingsSep 12, 2023Sep 12, 2023