Implement Multimodal RAG with ColPali and Vision Language Model Groq(Llava) and Qwen2-VL

Introduction
In Standard RAG the input document comprises of text data. The LLM takes advantage of in-context learning to provide more relevant and accurate answers by retrieving chunks of text documents matching the context of the query asked.
But what if the documents contains images ,tables ,plots etc. along with text data ?
Different Document Formats
- PDFs (Portable Document Format): Commonly used for sharing documents that preserve their formatting across platforms, but notoriously difficult to extract data from due to their unstructured layout.
- Microsoft Word documents (.doc, .docx): Flexible and widely used, but can include tables, images, headers, and footers, making extraction challenging.
- Excel spreadsheets (.xls, .xlsx): While Excel files are more structured, they can include complex multi-sheet data, merged cells, and formulas.
- Scanned images (.jpg, .png, .tiff): Scanned documents add another layer of complexity because they require Optical Character Recognition (OCR) to first convert images to text before extracting data.
- HTML and plain text files: While simpler to extract from, the diversity of possible layouts within these formats makes it non-trivial.
Each format has its own structure and challenges, but the real difficulty comes from the variations within those formats. For example, a PDF can be single-column or multi-column, may include tables or charts, and can have headers, footers, images, or diagrams. This wide range of possibilities makes it impractical to create a universal solution.
Key Challenges in processing such documents:
- Format Variability: Different formats have distinct characteristics that complicate data extraction. For instance, PDFs may contain images or tables, while scanned documents may have poor quality or handwriting.
- Data Integrity: Ensuring the accuracy and completeness of extracted data is crucial. Inaccurate data can lead to poor decision-making and operational inefficiencies.
- Volume Management: The increasing volume of documents can overwhelm traditional extraction methods, necessitating advanced solutions to handle large datasets effectively.
A standard LLM will overlook this additional information. Here RAG system has to rely on OCR tools to extract information from tables , images etc. But OCR accuracy is typically low for documents having complex formatting ,tables or images.Although OCR technology has improved significantly in recent years and is commonly used to extract text from scanned images. However, it still produces errors, especially with poor-quality scans, and struggles with complex layouts like multi-column PDFs or documents containing a mix of text and images. This will result in irrelevant or misinformed text chunks getting indexed which when retrieved and augmented into LLMs context can negatively impact the quality of answers synthesized by the LLM.
With the rapid advancement in Large Language Models and their ability to understand text and image we can use their ability to infer information from images, plots and tables.
Here we will use Multimodal LLM ColPali to infer the information from complex PDF documents.
What is ColPali ?
ColPali is a model based on a novel model architecture and training strategy based on Vision Language Models (VLMs) to efficiently index documents from their visual features. It is a PaliGemma-3B extension that generates ColBERT- style multi-vector representations of text and images. It was introduced in the paper ColPali: Efficient Document Retrieval with Vision Language Models
In a RAG system it is used as a Visual Retriever.

A key innovation of ColPali is mapping image patches into similar latent space as text .It unlocks efficient interaction between text and images using COLBERT Strategy.
ColPali builds on two observations:
- Multi-vector representations and late-interaction scoring improve retrieval performance.
- Vision language models have demonstrated extraordinary capabilities in understanding visual content.
ColPali is used to convert multimodal documents into image representations and then compute their multivector representation which will be stored as an index. This can be further used by VLM to answer questions.
What is COLBERT ?
ColBERT, which stands for Contextualized Late Interaction over BERT, is an innovative model designed for efficient information retrieval. It was introduced in the paper “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT”
Key Features of ColBERT:
- Token-Level Representations: Unlike traditional models that compress token representations into a single vector, ColBERT maintains individual embeddings for each token. This allows for more nuanced similarity calculations between query terms and document terms.
- Late Interaction Mechanism: ColBERT employs a late interaction strategy, where queries and documents are processed separately until the final stages of retrieval. This mechanism enhances efficiency by allowing for detailed comparisons without the need for exhaustive computations upfront.
- Improved Retrieval Performance: ColBERT has demonstrated superior performance on various benchmarks, even outperforming larger models in certain tasks. Its design enables it to handle complex queries and document structures effectively.
- Versions: The original ColBERT model has been succeeded by ColBERTv2, which incorporates enhancements such as denoised supervision and residual compression, further improving its effectiveness and efficiency in retrieval tasks.
ColBERT is particularly suited for applications requiring high precision in search tasks, making it a valuable tool in fields like natural language processing and information retrieval.
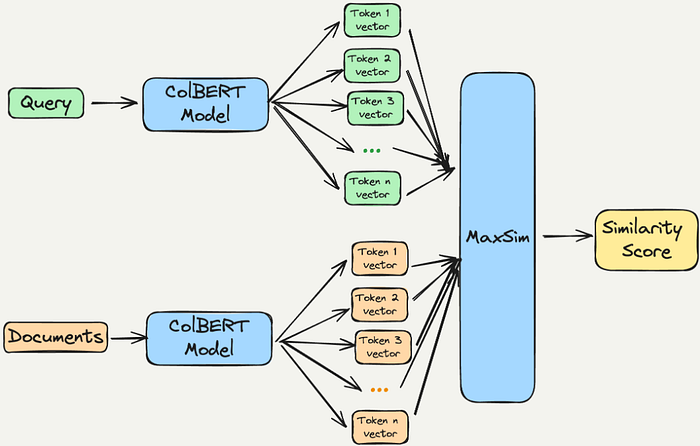

Early interaction can increase computational complexity since it requires considering all possible query-document pairs, making it less efficient for large-scale applications.
Late interaction models like ColBERT optimize for efficiency and scalability by allowing for the pre-computation of document representations and employing a more lightweight interaction step at the end, which focuses on the already encoded representations. This design choice enables faster retrieval times and reduced computational demands, making it more suitable for processing large document collections.
What is Vision Language Model ?
Vision Language Models (VLMs) are advanced AI systems that integrate both visual and textual information, enabling them to perform a variety of tasks that require understanding and generating text based on images. Here’s an overview of their key characteristics and applications:
Definition and Functionality
- Multimodal Learning: VLMs learn from images and their corresponding textual descriptions simultaneously. This allows them to associate visual features with linguistic expressions, enhancing their ability to understand context and semantics in both modalities .
- Generative Capabilities: These models can generate text outputs based on image inputs, making them useful for tasks like image captioning, where they create descriptive text for given images .
Key Features
- Image and Text Encoding: VLMs typically consist of separate encoders for images and text. They fuse information from these encoders to achieve a comprehensive understanding of the input data .
- Zero-Shot Learning: Many VLMs exhibit strong zero-shot capabilities, meaning they can generalize well to new tasks without needing additional training data .
- Spatial Awareness: Some models can capture spatial relationships within images, allowing them to output bounding boxes or segmentation masks when identifying specific objects or areas in an image
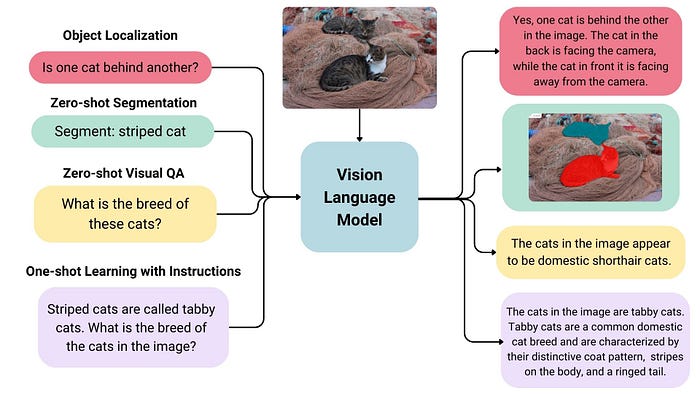
Multimodal RAG Implementation Step:
- The Required input document is encoded with ColPali and the resulting embeddings are indexed and stored in a VectorStore.
- The user query is then encoded with ColPali and resulting embeddings are used to retrieve similar chunks of documents from the VectorStore that may contain text and images.
- RAG system then uses the retrieved chunk as input to augment the context with the user query to facilitate a VLM to respond to user query.
Several vector databases support multi-vector architecture or ColBERT-style representations, enabling efficient indexing and retrieval of high-dimensional vector data. Here are some notable options:
- Vespa: Vespa has introduced multi-vector support, allowing the indexing of multiple vectors per document. This feature enables the retrieval of documents based on the closest vector in each, making it suitable for complex data representations and semantic search applications .
- Pinecone: Pinecone is designed for managing vector embeddings and supports advanced querying capabilities, including handling multiple vector representations. It is optimized for AI applications, making it a strong candidate for tasks that require nuanced data representation .
- Qdrant: Qdrant is a specialized vector database that efficiently indexes and retrieves high-dimensional vector data. While it primarily focuses on single vector embeddings, it is adaptable for various architectures, including those that may require multi-vector setups
Technology Stack Required
- Transformers library for running Qwen2-VL-7b-Instruct VLM.
- Flash Attention is required if we want to run VLM (Qwen2-VL) on a consumer GPU(24 GB VRAM).
- Byaldi is a wrapper on ColPali Repository which makes very easy to use ColPali for RAG
- qwen_vl_utils to facilitate input processing for Qwen-VL.
- pdf2image is used to convert PDF pages into images. This is necessary since Qwen2-VL cannot encode PDF files.
- popller-utils is required by byaldi to index PDF pages.
- Groq to use Llava model as VLM and check the quality of reponse
Code Implementation
- google colab Nvidia A100
- Install required dependencies
!pip install -qU byaldi
!pip install -qU accelerate
!pip install -qU flash_attn
!pip install -qU qwen_vl_utils
!pip install -qU pdf2image
!pip install -qU groq
!python -m pip install git+https://github.com/huggingface/transformers!sudo apt-get update
!apt-get install poppler-utils- download data
!mkdir Data
!wget https://arxiv.org/pdf/2409.06697 -O Data/input.pdf- import required dependencies
from byaldi import RAGMultiModalModel
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
from pdf2image import convert_from_path
import groq- Load the ColPali with RAGMultiModal from byaldi
RAG = RAGMultiModalModel.from_pretrained("vidore/colpali")- Load the vision Model
model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="cuda")- Index PDF files with byaldi
RAG.index(input_path="Data/input.pdf",
index_name="multimodal_rag",
store_collection_with_index=False,
overwrite=True,)- Retrieve context from Vectorstore based on the user query
text_query = "What is the type of star hosting thge kepler-51 planetary system?"
results = RAG.search(text_query,k=3)
results
###### RESPOSNE #####
[{'doc_id': 1, 'page_num': 1, 'score': 25.125, 'metadata': {}, 'base64': None},
{'doc_id': 1, 'page_num': 8, 'score': 24.875, 'metadata': {}, 'base64': None},
{'doc_id': 1, 'page_num': 9, 'score': 24.125, 'metadata': {}, 'base64': None}]- Convert to actual Image Data
images = convert_from_path("Data/input.pdf")
image_index = results[0]["page_num"] -1- display the Chosen Document Image
from IPython.display import Image,display
display(images[image_index])
from IPython.display import Image,display
display(images[1])
- save the image
from PIL import Image
# Assuming 'img' is your image object
images[image_index].save('image1.jpg')- setup Groq Api Key
from google.colab import userdata
import os
os.environ["GROQ_API_KEY"] = userdata.get("GROQ_API_KEY")- Synthesize response using GROQ — llava-v1.5–7b-4096-preview model
LLaVA V1.5 7B (Preview)-Groq
- Model ID: llava-v1.5–7b-4096-preview
- Description: LLaVA (Large Language-and-Vision Assistant) is an open-source, fine-tuned multimodal model that can generate text descriptions of images, achieving impressive performance on multimodal instruction-following tasks and outperforming GPT-4 on certain benchmarks.
- Context Window: 4,096 tokens
Limitations
- Preview Model: Llava V1.5 7B is currently in preview and should be used for experimentation.
- Image Size Limit: The maximum allowed size for a request containing an image URL as input is 20MB.
- Requests larger than this limit will return a 400 error.
- Request Size Limit (Base64 Enconded Images): The maximum allowed size for a request containing a base64 encoded image is 4MB. Requests larger than this limit will return a 413 error.
- Single Image per Request: Only one image can be processed per request. Requests with multiple images will return a 400 error.
- Single User Message per Request: Multi-turn conversations are not currently supported and only one user message is allowed per request. Requests with multiple user messages will return a 400 error.
- No System Prompt or Assistant Message: System messages and assistant messages are currently not supported. Requests including system or assistant messages will return a 400 error.
- No Tool Use: Tool Use is not currently supported. Requests with tool use or function calling will return a 400 error.
- No JSON Mode: JSON Mode is not currently supported. Requests with JSON Mode enabled will return a 400 error.
from groq import Groq
import base64
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "/content/image1.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
client = Groq()
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": text_query},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
},
},
],
}
],
model="llava-v1.5-7b-4096-preview",
)
print(chat_completion.choices[0].message.content)
## Response ##
The type of star hosting the Kepler-51 planetary system is a F-type main-sequence star, known as Fp Lacertae. This star is located at roughly 3,090 light-years from Earth. Fp Lacertae is considered a B-type dwarf star, meaning it emits a relatively larger amount of intense light, and the planet Kepler 51i is seen orbitsing the star.- Using QWEN2-VL-7B-INSTRUCT Vision Language model for response synthesis
messages = [
{"role":"user",
"content":[{"type":"image",
"image":images[image_index]
},
{"type":"text","text":text_query}
]
}
]
#
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
#
image_inputs,video_inputs = process_vision_info(messages)
#
inputs = processor(text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt")
inputs = inputs.to("cuda")
#
generate_ids = model.generate(**inputs,
max_new_tokens=256)
#
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generate_ids)]
#
output_text = processor.batch_decode(generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
#
print(output_text[0])
#### RESPONSE ####
'The host star of the Kepler-51 planetary system is a G-type star.'Here we observe that Qwen2-VL presents more accurate and better results.
- ask another query
text_query = "What is the age of the star hosting the kepler-51 planetary system?"
#
messages = [
{"role":"user",
"content":[{"type":"image",
"image":images[image_index]
},
{"type":"text","text":text_query}
]
}
]
#
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
#
image_inputs,video_inputs = process_vision_info(messages)
#
inputs = processor(text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt")
inputs = inputs.to("cuda")
#
generate_ids = model.generate(**inputs,
max_new_tokens=256)
#
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generate_ids)]
#
output_text = processor.batch_decode(generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
#
print(output_text[0])
#
################ RESPONSE ##################################
The host star is a G-type star of age ~500 Myr.Conclusion
ColPali represents a significant advancement in multimodal document retrieval, combining the strengths of VLMs with innovative architectural choices. Its ability to process and retrieve information from complex documents efficiently positions it as a valuable tool in the evolving landscape of AI-driven data analysis and retrieval systems.
Here we have build a Multimodal RAG pipeline using ColPali as the visual retriever and Qwen2-VL as the Vision Language Model. We have also measured the performance with Llava Model.
References:
Note: The above experiment was done by referring materials online. In no way I claim the code to be an original effort. It is out of the sole intention of acquiring knowledge.

